RESEARCH↑ trendingReddit r/MachineLearning·il y a 27j
Learning, Fast and Slow: Towards LLMs That Adapt Continually [R]
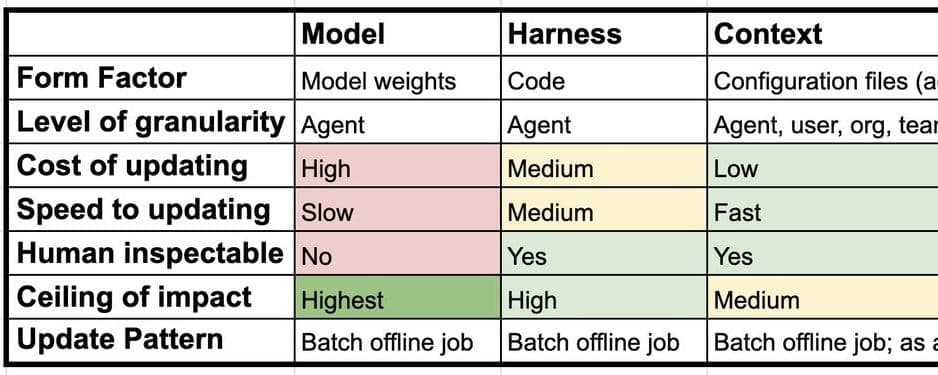
Les grands modèles linguistiques (LLM) sont confrontés à l'oubli catastrophique et à la perte de plasticité lors de la mise à jour de leurs paramètres pour des tâches spécifiques. Ce travail introduit un cadre d'apprentissage "rapide-lent" pour les LLM, utilisant les paramètres du modèle comme poids lents et le contexte optimisé comme poids rapides pour s'adapter efficacement sans compromettre le raisonnement général.
42